|
|
|
|||||
|
|||||
REMARKS ON THE STRUCTURE OF DISCOURSE
Language and Linguistics Symposium
INTRODUCTIONIn this paper I will adduce data which suggest that syntactic relations exist not only between constituents within sentences, but also between the sentences or larger fragments of which discourse consists. To account for the data, I will propose an extension of Junction Grammar and illustrate the proposal by diagramming representative units of discourse larger than sentences. DISCOURSE LEVEL JUNCTIONLet us first consider evidence which suggests that conjunction occurs at discourse level. ConjunctionA coordinating conjunction often occurs as the initial capitalized word of a sentence (Illustration 1). Moreover, it is standard procedure in composition to break up long sentences by replacing semi-colons with periods. Such modifications seem to change nothing in the way of junction relations. The fact that And, Or, or But is capitalized and preceded by a punctuation mark does not abrogate the junction relation between the clause preceding it and the clause following it (see Illustration 1). In still other cases, although no conjunctive marker occurs overtly, a conjunction relation is clearly felt and would therefore need to appear in the underlying representation.
All of this implies, of course, that sentences, notwithstanding capital letters or other punctuation, are constituents of a yet larger unit. Further support for this view are examples like those of Illustration 1, where the conjunction seems to span a paragraph indentation. This suggests that units as large as paragraphs are structured in such a way that they form a unit whole. Otherwise, they could not function as constituents in a conjunction. Thus, the evidence leads one to suspect that syntax extends beyond sentence level to discourse level, interrelating elements of discourse to form paragraphs, sections, chapters, and so on. SubjunctionInstances of discourse-level modification can also be cited. I draw your attention to vocatives and salutary expressions commonly used to preface what is said or written. Consider the specific case of a letter, where the salutation directs the entire contents of the text to a given person or persons (see Illustration 2). It would be incorrect to represent such expressions as modifiers of the closest sentence -their domain is more extensive than that.
Besides the salutary and vocative modifiers in question, there are interjections which express the reaction of the hearer or speaker to entire stretches of conversation or writing (see Illustration 3). These, too, confirm the existence of constituents larger than sentences that have modifiers in their own right.
Other instances of discourse level modification are even more transparent. Illustration 4 depicts an excerpt from BYU'sDaily Universe.Notice that which in this instance is a relative pronoun whose antecedent is the preceding paragraph. One can cite other forms as well that seem to function as connectives at discourse level. In fact, there are examples which correspond nicely to relative modifiers, complement modifiers, and appositive modifiers, all of them at discourse level. Before discussing these, however, let us turn our attention to the descriptive problem posed by such data.
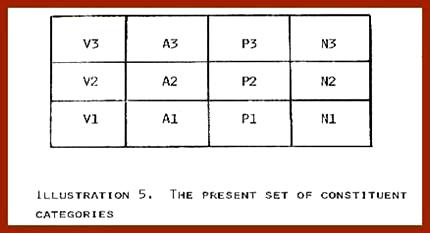
DESCRIPTIVE ALTERNATIVESAssuming that syntactic relations do exist at discourse level, a systematic grammar is needed to represent them. Since, for our purposes, it would be advantageous to represent discourse structure in terms of junction relations, thus averting the need to develop a separate grammar, let us consider some alternatives which suggest themselves for this purpose. The Addition of Discourse OperandsJunction Grammar utilizes junction rules to account for syntactic relations within sentences. These rules are expressed in terms of operands, i.e. grammatical constituents of various categories, and operations upon these operands (conjunction, adjunction, subjunction, and categorization, or the labeling operation). There is no obvious reason to exclude either new operations or new operands should this be necessary to account for the data. In fact, one's first inclination is to simply add operands such as SENTENCE, PARAGRAPH, PART, etc. The simplistic tone of this solution, however, is quickly betrayed by the nature of the problems to which it gives rise. Permit me to elaborate briefly. It turns out that the number of such categories required to account for the organization of printed materials becomes indefinitely large. In some texts, discourse constituents are labeled by titles or numbers based on some generally consistent procedure for dividing and subdividing; in others, such as scripture, only ROOK, CHAPTER, and VERSE are used; in poetry and song, we find PARTS, STANZAS, VERSES, CHORUSES, and so on; and some works consist of multiple volumes with highly elaborate organizational schemes. That there should be many discourse categories is not necessarily disturbing per se, but the proliferation of junction rules that results is somewhat disquieting. Of course, one could make a distinction between, say, low-level junction rules and high-level junction rules, resulting in two distinct sets of rules. A division of this sort, however, breaks down quickly, because there seem to be cases where both high and low-level operands would appear in the same rule. Although a system of constraints might conceivably be worked out to make such a system viable, there are other questions of substance that must also be resolved. In the first place, the present set of twelve constituent categories (Illustration 5) is based on contrasts which are grammatically significant.
Presumably, this is related to the fact that they represent basic sememic categories (noun, verb, preposition, etc.) or predication categories derived from these via adjunction (SV, PV, etc.). Categories such as SENTENCE and PARAGRAPH, however, correspond to neither of these classifications, i.e. they are neither sememic nor derived via adjunction, and do not appear to be grammatically significant. This assertion is supported by the fact that speakers will consistently identify members of the present set of operands because of their behavior and meaning, but falter when it comes to identifying the discourse categories of the types proposed. Thus, given an unpunctuated text, we can readily identify nouns, verbs, clauses, etc., but will hesitate and disagree among ourselves regarding the placement of periods, semicolons, paragraph indentations, and so on. In short, whereas the meaning and general behavior of the present inventory of operands permits one to justify them as legitimate grammatical constituents on syntacto-semantic grounds, it is not at all clear that the discourse operands in question can be similarly justified. Another counter-indication for discourse operands of the type under consideration is the occurrence of fragments such as those shown in Illustration 6. Notice that the paragraph following must consists of a complex predicate construction rather than a sentence or complex of sentences. The point to be noted here is that being a PARAGRAPH does not nullify or in any way obscure the grammatical identity of this fragment as a verbal predicate construction (PV). The same appears to be true of other discourse fragments set off as PARAGRAPHS. Their grammatical category as clausal constituents of varying degrees of complexity remains in force notwithstanding their status as PARAGRAPH.
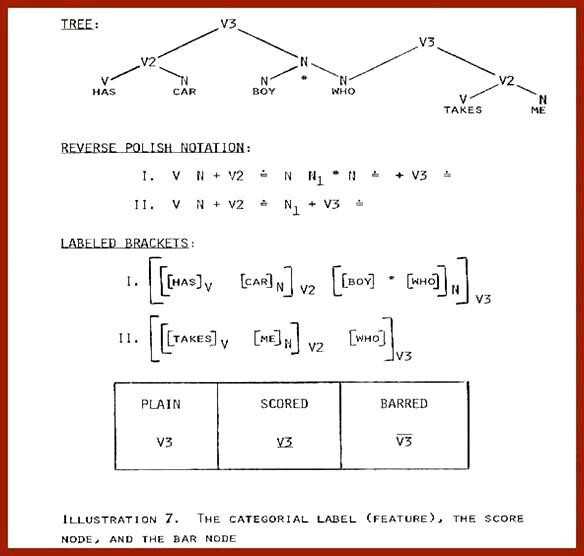
These observations suggest either that (1) some sort of derivation is involved or that (2) the proposed discourse categories and the twelve constituent categories utilized by the present set of junction rules are distinct and independent classification systems. The second assumption is borne out by a perhaps subtle but significant property of the proposed discourse categories: not only do they overlap with existing operand categories, they also overlap each other. It is often the case that a SENTENCE is also a PARAGRAPH, or perhaps a VERSE. Notice, on the other hand, that a grammatical constituent cannot be an SX (clause) and a PX (predicate) simultaneously. In fact, constituent categories never overlap except as the result of a derivational process. Since I see nothing associated with the data in question which suggests that we are dealing with a derivational phenomenon, the assumption that discourse categories and constituent categories are independent of each other seems to be the best one. Having reached this conclusion, a new set of questions comes to mind. First, if discourse categories are not constituent categories, then how are we to regard them? Second, how are they to be specified by the grammar? And third, how do they result in the textual demarcations that we are familiar with? Let us consider each of these questions in order. Discourse Categories as DelimitersThe cross categorization we have observed for discourse categories, as well as their indefinite variety, suggests that they should be dealt with as feature entitles, since the latter are also characterized by these properties. I propose that we consider them to be a system of delimiting features whose function is to specify a hierarchy of discourse fragments which stimulate either the distinctive voice modulations or the punctuation markers with which we are familiar. This implies that delimiters will be annotated as feature specifications of grammatical constituents in the same way that other features are. This brings us to the second question: how are such features to be specified by the grammar? A Generalization of the Labeling OperatorSeveral alternatives suggest themselves for formalizing the specification of delimiting features. Another operation, say #, could be added, which would assign them. This, however, would seem superfluous, since a categorizing operation is already available in the grammar. In saying this, I am assuming that it is immaterial whether we refer to SENTENCE, PARAGRAPH, etc. as delimiting categories or delimiting features. In other words, feature specifications are categorial designations of another variety. While on this subject, let me explain some notational nuances which will be helpful in understanding the formalization of Junction Grammar. In Illustration 7, a tree for a sentence with a relative modifier appears.
Reverse Polish notation for the tree is given as well as a labeled bracket representation for the kernel of the structure. The symbols in the tree can be interpreted in at least two ways: (1) They can be taken as symbols representing the constituent which they dominate; or (2) they can be taken as features specifying the categories of the constituents of which the tree consists. Notice, however, that the labeled bracketing is not ambiguous. Here the symbols are clearly categorial specifications attached to constituents, not constituents per se. Henceforth, I will use a plain symbol to represent a feature specifying the category of a constituent. An underscored symbol will represent a constituent plus its categorizing feature, and a barred (strikethrough in the current font) symbol will represent a labeled constituent (a score node) plus any structures intersecting with it, i.e. any relative modifiers. (See Illustration 7.) By implementing this notation in our junction rules, the essential difference between the junction operations (*, &, and +) and the categorizing operation (=) becomes clear. Specifically, the operands of junction operations are labeled constituents (i.e., score nodes), whereas the operands of the categorization operation are a constituent and a label (a categorizing feature). In other words, “=” assigns features to constituents (Illustration 8):
So that you may compare junction rules with the rewrite rules used by other grammars, here is a rewrite rule expressed in terms of the conventions I have described (Illustration 9): The rewrite arrow indicates that a complex constituent, S, is rewritten as (consists of) two constituents, an NP and a VP. Notice that the category of the constituents is implicitly rather than operationally assigned. The score, bar (strikethrough), and plain node distinctions become superfluous in the context of linguistic rules or reverse Polish notation, since the nature of a symbol is always clear from the operational context in which it occurs. The theoretical distinctions they reflect, however, are crucial, and it is necessary to annotate them when confusion may otherwise result. We now return to the problem of how to specify delimiting features. One's initial inclination is to generalize the use of ‘=’, allowing it to apply iteratively (Illustration 10):
This, however, results in a complication: V3 is enclosed within a delimiting bracket and is therefore not eligible in the usual way as an operand for another junction rule. We might add the convention that S (SENTENCE) has the same constituent value as its internal part (V3), and hus make S available as an operand in a J-rule. Or we could specify the delimiting category first and the syntactic category second (Illustration 11): VN + V2 = N + S = V3 = This would make the resultant unit eligible as an operand for the J-rules without any extra conventions, but the implication that delimitation is internal to V3 seems questionable. Another alternative, which is perhaps the best one, is to allow category specifications to be n-tuples consisting of concatenated elements, which can then be assigned as a complex symbol with one application of '=' (Illustration 12): V2N + V3 S, =
The comma signifies concatenation, which becomes another operation available to the grammar. This formulation has the advantage of being adaptable to yet another use. To date, feature specifications have been utilized in conjunction with WFSS's, but no formal device has been used to assign them. If features are considered to be another type of category specification, then there is no reason not to specify them by ‘=’ also. In other words, the set of possible semantic features becomes one of three general category designations specifiable by ‘=’ (Illustration 13): XY ○ GC, FC, DC
In the illustration, GC is the grammatical category, FCis the feature category, and DCIs the delimiting category. The concatenation operation can be used in such a way that the separate identities of GC, FC, and DC are maintained. This can be verified by constructing reverse Polish notation for various combinations which might occur. In Illustration 14, for example, a clause is categorized [V3; sentence; past, anterior]. This complex symbol of category designations is applied as a whole to the bracket by ‘=’.
DemarcationFor our present purposes, let us assume that a delimiter specified on Xiwill trigger punctuation rules which place the appropriate marker before and/or after the ordered SUBJUNCTION AT DISCOURSE LEVELLet us return to our discussion of discourse level subjunction. In addition to the salutary, vocative, and interjunction modifiers mentioned above, there are other instances of subjunction at discourse level. In fact, one can cite examples which correspond nicely to relative modifiers, complement modifiers, and appositive modifiers. Let us consider these in order. Relative ModifiersConsider the correspondence between the following pairs (Illustration 15):
1. He was hungry, so he ordered a hotdog. 1’. He was hungry. Hence he ordered a hotdog. 2. John refused to help, which made us mad. 2’. John refused to help. This made us mad. 3. The man screamed, he was so scared. 3’. The man screamed. He was that scared. 4. Lance Emery, who is my friend, volunteered to help. 4’. Lance Emery is my friend. He volunteered to help. Pairs of this sort occur interchangeably in our speech and writing. So far as I can tell, the elements of each pair contrast in their delimitation but not in the junction relations perceived in them. Thus, I propose that the selection of so (hence), this (which), so (that), who (he) is governed by the presence or absence of delimiters; hence, this, etc., have antecedents separated from them by a delimitive marker whereas who and which do not. I do not mean to imply that for all co-referential forms a relative relation holds . In some instances it is obvious that fragments are conjoined rather than subjoined, so that a relative relation between them is manifestly impossible (Illustration 16):
5. He was hungry and so he ordered a hot dog. But it does seem plausible to posit a relative relation when no conjunctive relation is felt. One reason for questioning this analysis perhaps is the morphological contrast between the alleged discourse level relative pro-forms and standard relative pro-forms. Insertion of the appropriate relative marker, however, could be governed by the presence or absence of a delimiter: Standard relative markers would occur at clause level; the alternate forms would occur in the context of a delimiter, in which case ordering and lexicalization are governed independently within the newly delimited fragment. There are cases where dual lexicalization occurs, yielding a standard relative marker on the first cycle and a standard pro-form on the second (Illustration 17).
6. A fellow who I don't know if he is dependable or not has applied for the job. In sentences such as this, the relative form occurs when the underlying intersect is first lexicalized as a reflection of its role in the main clause. The non-relative form, on the other hand, is produced on a subsequent cycle when the same node is lexicalized in connection with its role in the subordinate clause. It may be the case that delimitation of a relative clause results in a default to the second lexicalization option (the standard pro-form) and suppression of the first. Applying this supposition to (6) above, the result would seem to correspond to what is sometimes referred to as an interposed sentence: 6’. A fellow Ø (I don't know if he is dependable or not) has applied for the job. The null sign indicates where the relative pronoun would occur if the delimiter were not present. Complements and AppositivesThere is not time to discuss discourse level complements and appositives in any detail. For the present, an example of each will suffice.
In Illustration 18, a discourse fragment is depicted which seems to entail a delimited complement construction. Compare the example with “Gilford’s reply that he did not trust …” The delimitation of appositives seems to occur also. In Illustration 19, for example, the enumerating fragments are in apposition to factors.
DIAGRAMMING DISCOURSEThe application of the proposals I have made to diagramming the structure of discourse yields mixed results. In some instances it is immediately obvious what junction relations hold, but in others it is difficult to decide just what relationships are intended. In still other cases, the connectives are overt but ambiguous - it is not clear whether the antecedent is only the preceding sentence, or a larger fragment. One is tempted to conclude that many so-called paragraphs have run-on fragments; i.e. constituents which are not interrelated by rule but simply juxtaposed. In other instances, although no overt connective occurs, one can feel an and, or, but, because, or some other linking word between the juxtaposed fragments. For the time being, I have adopted the following conventions for analyzing the structure of discourse: (1) If an overt connective occurs, represent the appropriate relation with the corresponding junction rule. (2) If no overt connective occurs but one is clearly understood, represent the relation with the corresponding junction rule. (3) If no overt connective occurs and it is not clear how the fragments are joined, use an unspecified conjunction. Illustration 20 is a diagram of a paragraph selected from a magazine and illustrates the method I have proposed. There is nothing unusual about it. In fact, if the delimiters were removed, it would be realized as a lengthy clause.
IMPLICATIONSMore research, of course, will be required before a confident prognosis for the proposed approach can be made. However, to conclude my remarks, permit me to enumerate some of the positive results that could conceivably derive from the study of junction relations in discourse structure. First, the study of syntax in terms of sentence units alone imposes artificial limits on what we investigate, fostering what I believe is a rather myopic view of syntactic phenomena. The proposed extension of Junction Grammar eliminates this restriction. Second, the conscious awareness that sentences must be interrelated in specified ways may have a beneficial influence on the way one formulates his discourse. Hopefully, it will result in more intelligible speech and writing. Third, a formal system of representing the structure of discourse can facilitate automatic language processing by providing a medium for storing, manipulating, and retrieving natural language text. Last, but not insignificant by any means, a better system of punctuation may eventually emerge from studies of this type·
|
|
[Home] [Origins] [Article Archive] [Foundations] [Formalizations] [Analyses] [Pedadogy] [Forum] [Guest Book] [BYU] |
|
Copyright© 2004 Linguistic Technologies, Inc. |